For two decades, branded search was the safest territory in digital marketing. Type a brand name into Google, see the brand's own site at the top. The brand controlled the answer to its own name.
That guarantee has eroded. When a buyer asks ChatGPT or Perplexity to describe a brand, the answer is synthesized from whatever sources the engine trusts, which may not include the brand's own website as the primary source, and may not reflect how the brand describes itself at all.
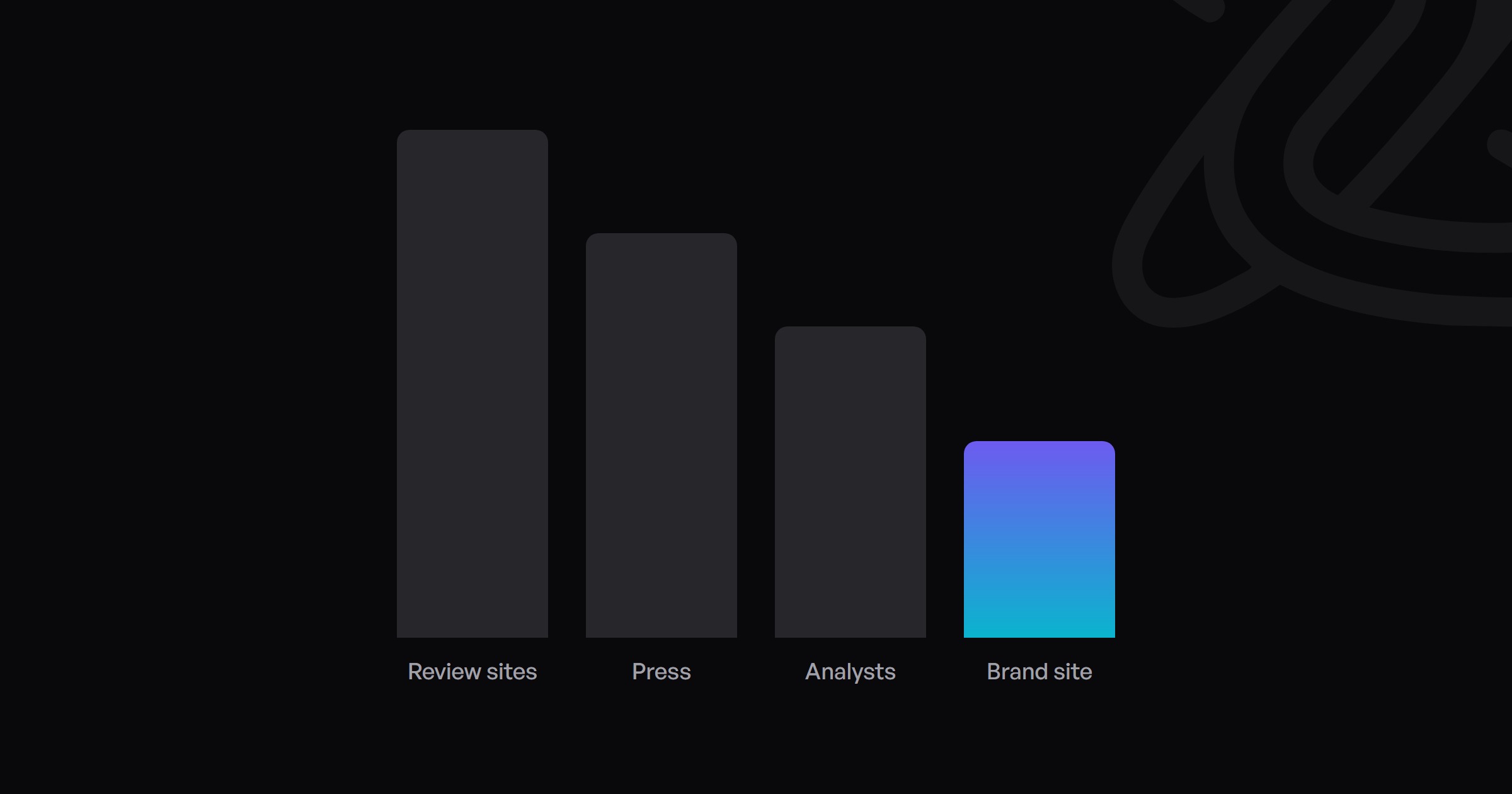
Most marketing teams have not audited this. They assume that if the brand ranks well in Google, it controls its narrative in AI answers too. The channels are poorly correlated, and the divergence is often large.
Key takeaways
- Branded queries in AI engines do not automatically surface the brand's own content. The AI answer is synthesized from third-party sources that may contradict or underweight the brand's own positioning.
- Brands lose narrative control when review sites, press coverage, and analyst commentary frame the brand differently than the brand frames itself. AI engines weight these third-party sources heavily because they are less incentivized to be self-promotional.
- Negative or neutral branded sentiment in AI answers is usually invisible to marketing teams until a prospect mentions it. Monitoring branded queries across engines is the only way to catch drift early.
- The two moves that protect branded visibility: establish a canonical entity definition that third parties use, and monitor branded queries monthly to detect narrative drift before it compounds.
What happens when a buyer asks about a brand
The query looks like: "tell me about [Brand]", "what does [Brand] do?", "is [Brand] worth it?", "what are the downsides of [Brand]?" These are branded queries. They should be the safest territory.
What the AI engine does is not retrieve the brand's homepage. It synthesizes from whatever sources in its training data and current web index have described the brand. If the dominant sources are review platforms with a neutral-to-mixed sentiment, an analyst report that positions the brand as a legacy option, and a comparison article that names three alternatives, then the AI answer will reflect those sources.
The brand's own messaging is one input among many. On most platforms, it is a lower-weighted input than third-party sources, precisely because it is recognized as the brand speaking for itself.
The narrative gap
Most brands have a gap between how they describe themselves and how third-party sources describe them. The gap is usually not adversarial. It is a drift problem: the brand updated its positioning last year, but review platforms, analyst reports, and press articles still use the old framing. The brand emphasizes a differentiator that third-party sources don't mention. The category language is inconsistent across sources.
This drift is invisible in Google rankings, where the brand's own site dominates for branded queries. In AI answers, the drift is the answer, because AI engines synthesize from the aggregate of available sources.
The larger the gap between owned messaging and third-party framing, the larger the narrative control problem in AI answers.
Why negative sentiment compounds
Negative sentiment in AI answers is self-reinforcing in a way that Google rankings are not. A Google result can be pushed down by improved content. An AI engine's negative framing of a brand persists as long as the sources contributing to that framing remain credible.
Worse, AI engines are often the place buyers form impressions before reaching the brand's own site. If a buyer asks Perplexity "is [Brand] right for us?" and receives a summarized answer that notes recurring complaints about support quality or pricing complexity, that impression enters the sales conversation without the brand knowing it was formed.
The only protection is monitoring. Teams that do not track what AI engines say about their brand when its name is queried have no visibility into the narrative that buyers are encountering before the first sales touchpoint.
The two moves that protect branded visibility
Establish a canonical entity definition. The canonical description is a two to three sentence statement of what the brand does, who it serves, and how it differentiates. Used consistently across every owned platform and pitched to publications as the description to quote, it creates a consistent signal that third-party sources can reflect. The more third-party sources use language consistent with the canonical description, the more AI answers about the brand reflect the brand's own framing.
This is not a guarantee of narrative control. It is a way to reduce the drift that leads to narrative gaps.
Monitor branded queries monthly. Run a set of fifteen to twenty branded queries across ChatGPT, Gemini, and Perplexity each month. Record the answers, note the sentiment, and flag any sources being cited that are carrying outdated or inaccurate framing. Monthly monitoring turns narrative drift from an invisible problem into a visible one.
The specific branded queries worth running: the brand name alone, the brand name plus the primary category ("is [Brand] a GEO platform?"), the brand name plus a use-case ("[Brand] for agencies"), and direct comparison queries ("[Brand] vs [Competitor A]"). These four query types collectively reveal the narrative that buyers encounter before they speak to anyone at the company.
For the broader framework of what AI visibility monitoring tracks and why the individual metrics matter, GEO metrics: what to track beyond mention rate covers the full measurement picture.